
Chapter 9 Graph Algorithms
9.1 Definitions
A graph
A path in a graph is a sequence of vertices
A cycle in a directed graph is a path of length at least
An undirected graph is connected if there is a path from every vertex to every other vertex. A directed graph with this property is called strongly connected. If a directed graph is not strongly connected, but the underlying graph (without direction to the arcs) is connected, then the graph is said to be weakly connected. A complete graph is a graph in which there is an edge between every pair of vertices.
9.1.1 Representation of Graphs
One simple way to represent a graph is to use a two-dimensional array. This is known as an adjacency matrix representation. For each edge A[u][v] to true.
Although this has the merit of extreme simplicity, the space requirement is
If the graph is not dense, in other words, if the graph is sparse, a better solution is an adjacency list representation. For each vertex, we keep a list of all adjacent vertices. The space requirement is then
9.2 Topological Sort
A topological sort is an ordering of vertices in a directed acyclic graph, such that if there is a path from
It is clear that a topological ordering is not possible if the graph has a cycle. Furthermore, the ordering is not necessarily unique; any legal ordering will do. In the graph,
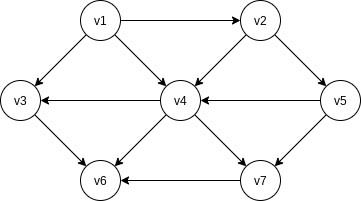
A simple algorithm to find a topological ordering is first to find any vertex with no incoming edges. We can then print this vertex, and remove it, along with its edges, from the graph. Then we apply this same strategy to the rest of the graph.
To formalize this, we define the indegree of a vertex
| Vertex | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 1 | 1 | 1 | 0 | 0 | 0 | |
| 3 | 2 | 1 | 0 | 0 | 0 | 0 | |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 3 | 3 | 3 | 3 | 2 | 1 | 0 | |
| 2 | 2 | 2 | 1 | 0 | 0 | 0 | |
| Enqueue | |||||||
| Dequeue |
void topsort() throws CycleFoundException {
Queue<Vertex> q = new Queue<Vertex>();
int counter = 0;
for (Vertex v: vertexList)
if (v.indegree == 0)
q.enqueue(v);
while (!q.isEmpty()) {
Vertex v = q.dequeue();
v.topNum = ++counter;
for (Vertex w: v.getAdjacentVertexList())
if (if --w.indegree == 0)
q.enqueue(w);
}
if (counter != NUM_VERTICES)
throw new CycleFoundException();
}We can remove this inefficiency by keeping all the (unassigned) vertices of indegree
9.3 Shortest-Path Algorithms
The input is a weighted graph: associated with each edge
Single-Source Shortest-Path Problem.
Given as input a weighted graph,
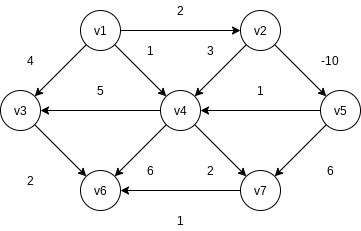
This loop is known as a negative-cost cycle; when one is present in the graph, the shortest paths are not defined.
9.3.1 Unweighted Shortest Paths
Using some vertex,
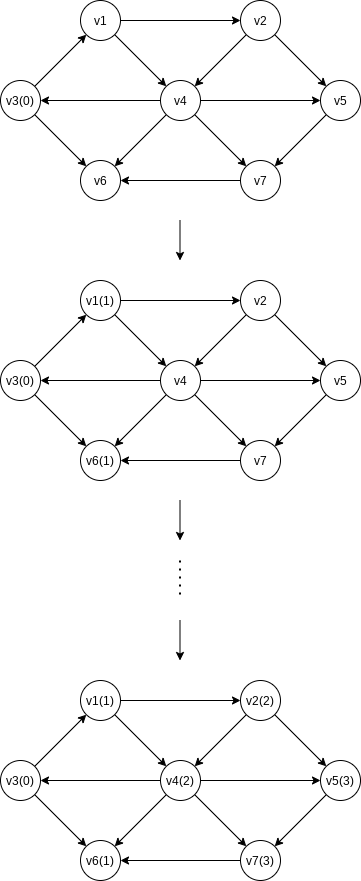
This strategy for searching a graph is known as breadth-first search. It operates by processing vertices in layers: The vertices closest to the start are evaluated first, and the most distant vertices are evaluated last. This is much the same as a level-order traversal for trees.
For each vertex, we will keep track of three pieces of information. First, we will keep its distance from
| v | known | ||
|---|---|---|---|
| F | 0 | ||
| F | 0 | ||
| F | 0 | 0 | |
| F | 0 | ||
| F | 0 | ||
| F | 0 | ||
| F | 0 |
void unweighted(Vertex s) {
for (Vertex v: vertexList) {
v.dist = INFINITY;
v.known = false;
}
s.dist = 0;
for (int currDist = 0; currDist < NUM_VERTICES; currDist++)
for (Vertex v: VertexList)
if (!v.known && v.dist == currDist) {
v.known = true;
for (Vertex w: v.getAdjacentVertexList())
if (w.dist == INFINITY) {
w.dist = currDist + 1;
w.path = v;
}
}
}The running time of the algorithm is NUM_VERTICES - 1, even if all the vertices become known much earlier.
We can remove the inefficiency in much the same way as was done for topological sort.
void unweighted(Vertex s) {
Queue<Vertex> q = new Queue<Vertex>();
for (Vertex v: vertexList)
v.dist = INFINITY;
s.dist = 0;
q.enqueue(s);
while (!q.isEmpty()) {
Vertex v = q.dequeue();
for (Vertex w: v.getAdjacentVertexList())
if (w.dist == INFINITY) {
w.dist = v.dist + 1;
w.path = v;
q.enqueue(w);
}
}
}9.3.2 Dijkstra’s Algorithm
The general method to solve the single-source shortest-path problem is known as Dijkstra’s algorithm. This thirty-year-old solution is a prime example of a greedy algorithm. Greedy algorithms generally solve a problem in stages by doing what appears to be the best thing at each stage.
In the unweighted case, we set
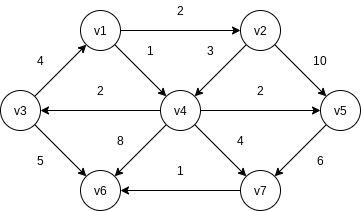
Initial configuration of table used in Dijkstra’s algorithm
v known F 0 0 F 0 F 0 F 0 F 0 F 0 F 0 After
is declared known v known T 0 0 F 2 F 0 F 1 F 0 F 0 F 0 After
is declared known v known T 0 0 F 2 F 3 T 1 F 3 F 9 F 5 After
is declared known v known T 0 0 T 2 F 3 T 1 F 3 F 9 F 5 After
and then are declared known v known T 0 0 T 2 T 3 T 1 T 3 F 8 F 5 After
is declared known v known T 0 0 T 2 T 3 T 1 T 3 F 6 T 5 After
is declared known and algorithm terminates v known T 0 0 T 2 T 3 T 1 T 3 T 6 T 5
class Vertex {
public List adj;
public boolean known;
public DistType dist;
public Vertex path;
}
public class Main() {
void printPath(Vertex v) {
if (v.path != null ) {
printPath(v.path);
System.out.print(" to ");
}
System.out.print(v);
}
void dijkstra(Vertex s) {
for (Vertex v: vertexList) {
v.dist = INFINITY;
v.known = false;
}
s.dist = 0;
while (vertexList.hasUnknownVertex()) {
Vertex v = vertexList.getSmallestUnknownDistanceVertex();
v.known = true;
for (Vertex w: v.getAdjacentVertexList())
if (!w.known) {
DistType cvw = cost(v, w);
if (v.dist + cvw < w.dist) {
w.dist = v.dist + cvw;
w.path = v;
}
}
}
}
}9.3.4 Acyclic Graphs
If the graph is known to be acyclic, we can improve Dijkstra’s algorithm by changing the order in which vertices are declared known, otherwise known as the vertex selection rule. The new rule is to select vertices in topological order.
This selection rule works because when a vertex
There is no need for a priority queue with this selection rule; the running time is
A more important use of acyclic graphs is critical path analysis. Each node represents an activity that must be performed, along with the time it takes to complete the activity. This graph is thus known as an activity-node graph.
To perform these calculations, we convert the activity-node graph to an event-node graph. Each event corresponds to the completion of an activity and all its dependent activities.
To find the earliest completion time of the project, we merely need to find the length of the longest path from the first event to the last event. For general graphs, the longest-path problem generally does not make sense, because of the possibility of positive-cost cycles. These are the equivalent of negative-cost cycles in shortest-path problems.
9.4 Network Flow Problems
Suppose we are given a directed graph
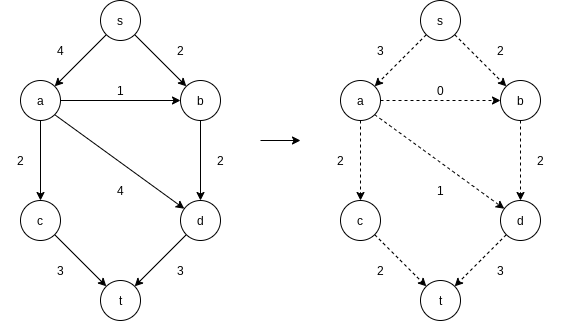
9.4.1 A Simple Maximum-Flow Algorithm
A first attempt to solve the problem proceeds in stages. We start with our graph,
At each stage, we find a path in
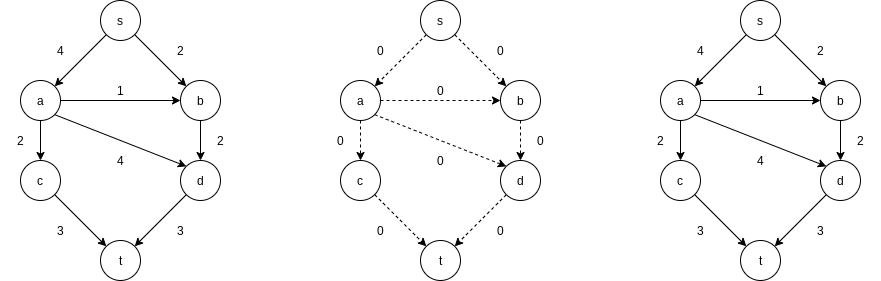
There are many paths from s to t in the residual graph. Suppose we select
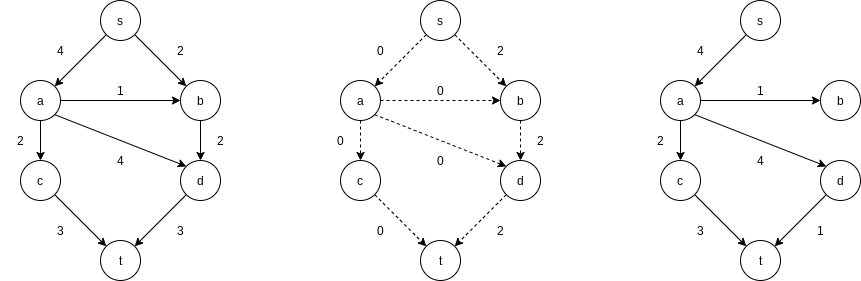
Next, we might select the path
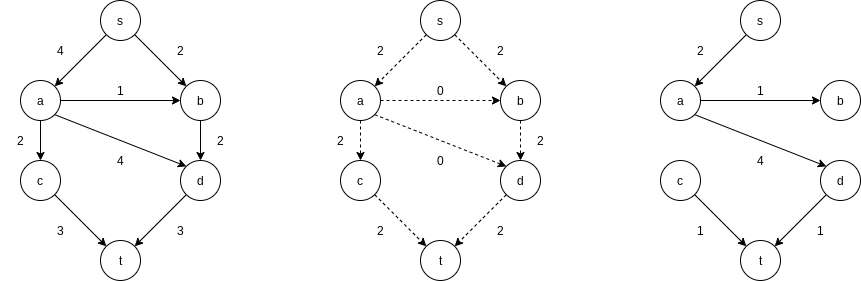
The only path left to select is
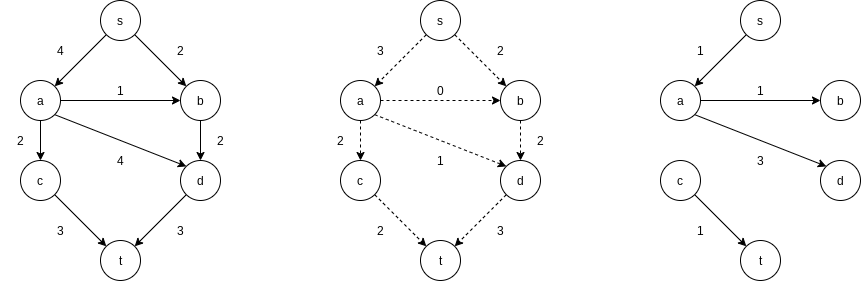
The algorithm terminates at this point, because
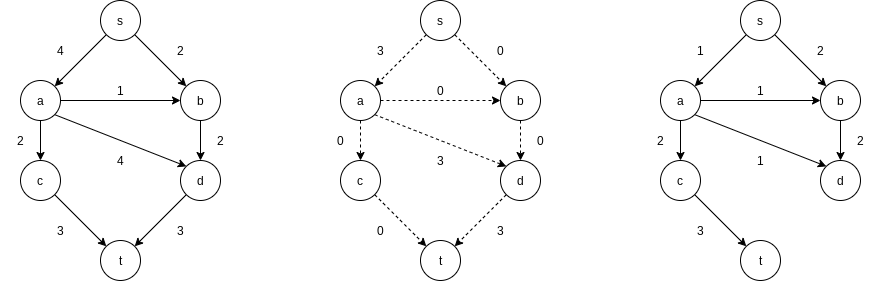
In order to make this algorithm work, we need to allow the algorithm to change its mind. To do this, for every edge
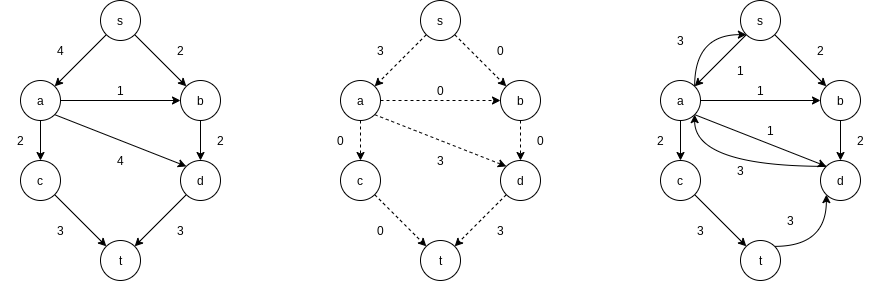
Notice that in the residual graph, there are edges in both directions between
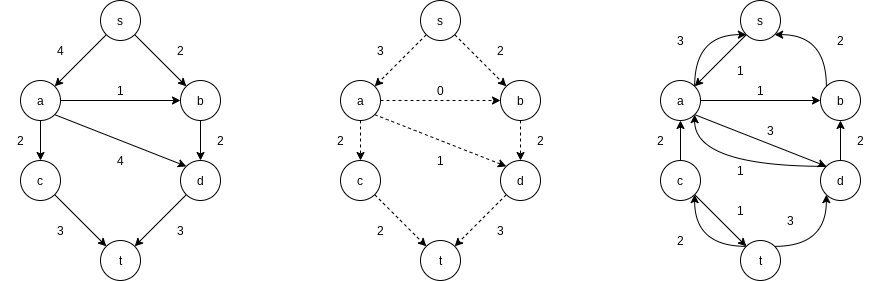
A simple method to get around this problem is always to choose the augmenting path that allows the largest increase in flow. Finding such a path is similar to solving a weighted shortest-path problem and a single-line modification to Dijkstra’s algorithm will do the trick. If
9.5 Minimum Spanning Tree
Informally, a minimum spanning tree of an undirected graph
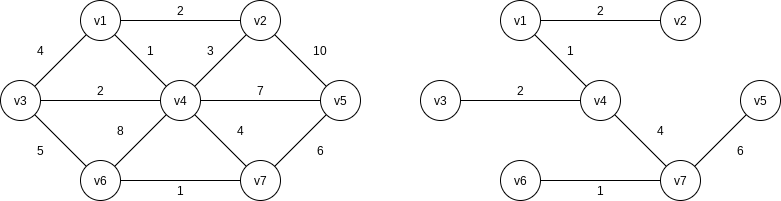
9.5.1 Prim’s Algorithm
One way to compute a minimum spanning tree is to grow the tree in successive stages. In each stage, one node is picked as the root, and we add an edge, and thus an associated vertex, to the tree.
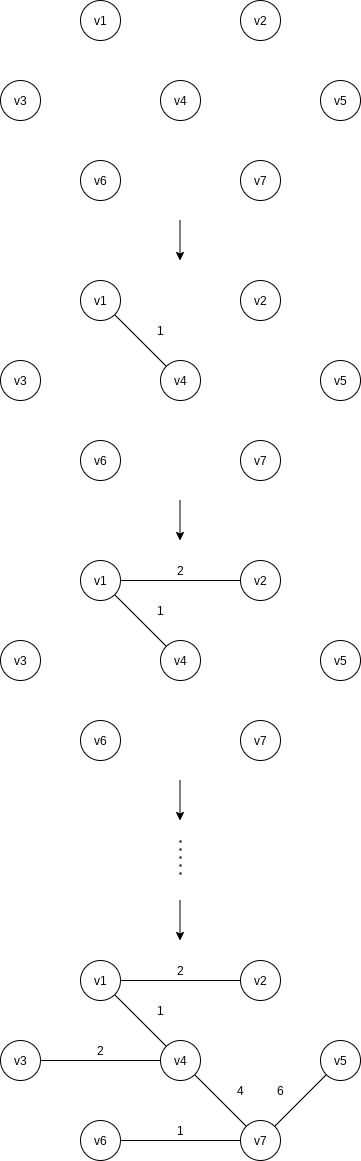
We can see that Prim’s algorithm is essentially identical to Dijkstra’s algorithm for shortest paths. As before, for each vertex we keep values
9.5.2 Kruskal’s Algorithm
Formally, Kruskal’s algorithm maintains a forest – a collection of trees. Initially, there are
The algorithm terminates when enough edges are accepted. It turns out to be simple to decide whether edge
| Edge | Weight | Action |
|---|---|---|
| 1 | Accepted | |
| 1 | Accepted | |
| 2 | Accepted | |
| 2 | Accepted | |
| 3 | Rejected | |
| 4 | Rejected | |
| 4 | Accepted | |
| 5 | Rejected | |
| 6 | Accepted |
The invariant we will use is that at any point in the process, two vertices belong to the same set if and only if they are connected in the current spanning forest.
ArrayList<Edge> kruskal(List<Edge> edges, int numVertices) {
DisjSets ds = new DisjSets(numVertices);
PriorityQueue<Edge> pq = new PriorityQueue<>(edges);
List<Edge> mst = new ArrayList<>();
while (mst.size() != numVertices - 1) {
Edge e = pq.deleteMin();
SetType uset = ds.find(e.getu());
SetType vset = ds.find(e.getv());
if (uset != vset) {
mst.add(e);
ds.union(uset, vset);
}
}
return mst;
}The worst-case running time of this algorithm is
9.6 Applications of Depth-First Search
Depth-first search is a generalization of preorder traversal. Starting at some vertex,
void dfs(Vertex v) {
v.visited = true;
for (Vertex w: v.getAdjacentVertexList())
if (!w.visited)
dfs(w);
}9.6.2 Biconnectivity
A connected undirected graph is biconnected if there are no vertices whose removal disconnects the rest of the graph.
If a graph is not biconnected, the vertices whose removal would disconnect the graph are known as articulation points.
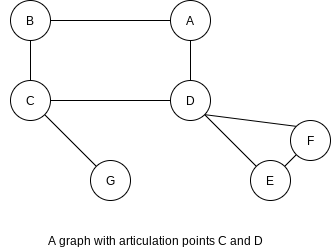
Depth-first search provides a linear-time algorithm to find all articulation points in a connected graph. First, starting at any vertex, we perform a depth-first search and number the nodes as they are visited. For each vertex Num(v). Then, for every vertex Low(v), that is reachable from
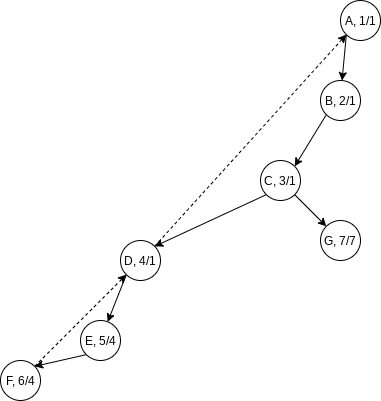
We can efficiently compute Low by performing a postorder traversal of the depth-first spanning tree. By the definition of Low, Low(v) is the minimum of:
Num(v)- the lowest
Num(w)among all back edges - the lowest
Low(w)among all tree edges
All that is left to do is to use this information to find articulation points. The root is an articulation point if and only if it has more than one child. Any other vertex
void assignNum(Vertex v) {
v.num = counter++;
v.visited = true;
for (Vertex w: v.getAdjacentVertexList())
if (!w.visited) {
w.parent = v;
assignNum(w);
}
}
void assignLow(Vertex v) {
v.low = v.num;
for (Vertex w: v.getAdjacentVertexList()) {
if (w.num > v.num) {
assignLow(w);
if (w.low >= v.num)
System.out.println(v + " is an articulation point");
v.low = min(v.low, w.low);
} else if (v.parent != w)
v.low = min(v.low, w.num);
}
}9.6.4 Directed Graphs
Using the same strategy as with undirected graphs, directed graphs can be traversed in linear time, using depth-first search. If the graph is not strongly connected, a depth-first search starting at some node might not visit all nodes.
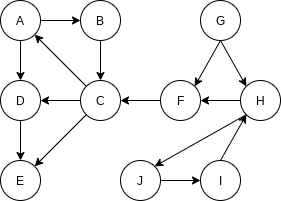
We arbitrarily start the depth-first search at vertex
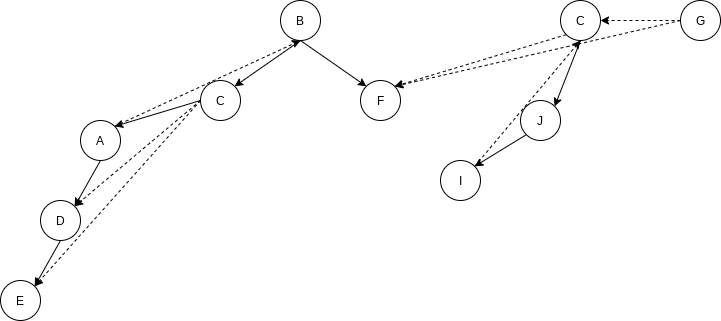
9.6.5 Finding Strong Components
By performing two depth-first searches, we can test whether a directed graph is strongly connected, and if it is not, we can actually produce the subsets of vertices that are strongly connected to themselves.
First, a depth-first search is performed on the input graph
The algorithm is completed by performing a depth-first search on
9.7 Introduction to NP-Completeness
9.7.1 Easy vs. Hard
Just as real numbers are not sufficient to express a solution to
One particular undecidable problem is the halting problem. Is it possible to have your Java compiler have an extra feature that not only detects syntax errors, but also all infinite loops? This seems like a hard problem, but one might expect that if some very clever programmers spent enough time on it, they could produce this enhancement.
The intuitive reason that this problem is undecidable is that such a program might have a hard time checking itself. For this reason, these problems are sometimes called recursively undecidable.
9.7.2 The Class NP
NP stands for nondeterministic polynomial-time. A deterministic machine, at each point in time, is executing an instruction. Depending on the instruction, it then goes to some next instruction, which is unique. A nondeterministic machine has a choice of next steps. It is free to choose any that it wishes, and if one of these steps leads to a solution, it will always choose the correct one. Furthermore, nondeterminism is not as powerful as one might think. For instance, undecidable problems are still undecidable, even if nondeterminism is allowed.
Notice also that not all decidable problems are in NP. Consider the problem of deter mining whether a graph does not have a Hamiltonian cycle. To prove that a graph has a Hamiltonian cycle is a relatively simple matter – we just need to exhibit one. Nobody knows how to show, in polynomial time, that a graph does not have a Hamiltonian cycle. It seems that one must enumerate all the cycles and check them one by one. Thus the Non-Hamiltonian cycle problem is not known to be in NP.
9.7.3 NP-Complete Problems
An NP-complete problem has the property that any problem in NP can be polynomially reduced to it.
A problem
Traveling Salesman Problem.
Given a complete graph
The traveling salesman problem is NP-complete. It is easy to see that a solution can be checked in polynomial time, so it is certainly in NP. To show that it is NP-complete, we polynomially reduce the Hamiltonian cycle problem to it. To do this we construct a new graph
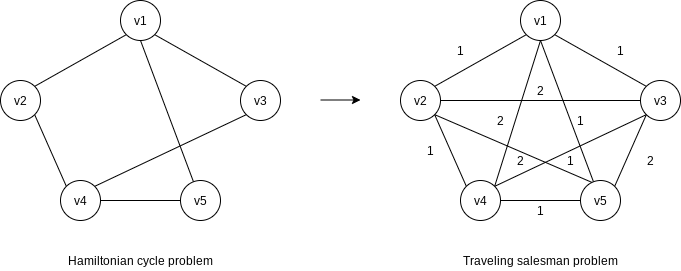
It is easy to verify that
The first problem that was proven to be NP-complete was the satisfiability problem. The satisfiability problem takes as input a Boolean expression and asks whether the expression has an assignment to the variables that gives a value of true.