
Chapter 8 The Disjoint Set Class
8.1 Equivalence Relations
A relation
An equivalence relation is a relation
- (Reflexive)
, for all . - (Symmetric)
if and only if . - (Transitive)
and implies that .
8.2 The Dynamic Equivalence Problem
Given an equivalence relation
The equivalence class of an element
The input is initially a collection of
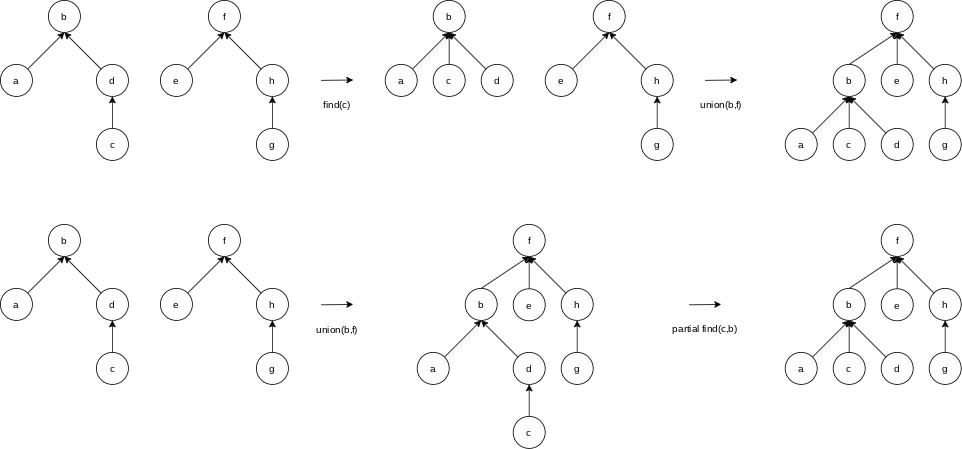
There are two permissible operations. The first is find, which returns the name of the set (that is, the equivalence class) containing a given element. The second operation adds relations. If we want to add the relation union. This operation merges the two equivalence classes containing
This algorithm is dynamic because, during the course of the algorithm, the sets can change via the union operation. The algorithm must also operate online: When a find is performed, it must give an answer before continuing. Another possibility would be an off-line algorithm.
Notice that we do not perform any operations comparing the relative values of elements but merely require knowledge of their location. For this reason, we can assume that all the elements have been numbered sequentially from
Our second observation is that the name of the set returned by find is actually fairly arbitrary. All that really matters is that find(a) == find(b) is true if and only if
There are two strategies to solve this problem. One ensures that the find instruction can be executed in constant worst-case time, and the other ensures that the union instruction can be executed in constant worst-case time. It has been shown that both cannot be done simultaneously in constant worst-case time.
We will now briefly discuss the first approach. For the find operation to be fast, we could maintain, in an array, the name of the equivalence class for each element. Then find is just a simple union(a, b). Suppose that find operations, this performance is fine, since the total running time would then amount to union or find operation over the course of the algorithm. If there are fewer finds, this bound is not acceptable.
One idea is to keep all the elements that are in the same equivalence class in a linked list. This saves time when updating, because we do not have to search through the entire array. This by itself does not reduce the asymptotic running time, because it is still possible to perform
If we also keep track of the size of each equivalence class, and when performing unions we change the name of the smaller equivalence class to the larger, then the total time spent for
8.3 Basic Data Structure

Using the strategy above, it is possible to create a tree of depth find is
8.4 Smart Union Algorithms
The unions above were performed rather arbitrarily, by making the second tree a subtree of the first. A simple improvement is always to make the smaller tree a subtree of the larger, breaking ties by any method; we call this approach union-by-size.
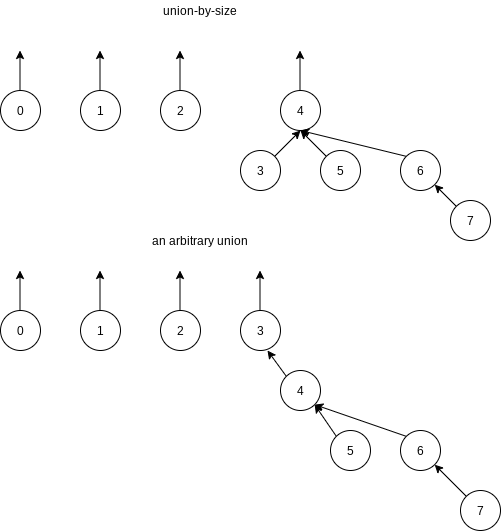
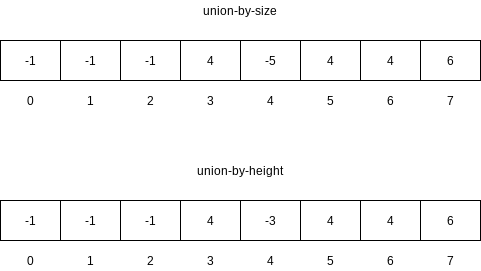
To implement this strategy, we need to keep track of the size of each tree. Since we are really just using an array, we can have the array entry of each root contain the negative of the size of its tree. Thus, initially the array representation of the tree is all union is performed, check the sizes; the new size is the sum of the old. Thus, union-by-size is not at all difficult to implement and requires no extra space. It is also fast, on average.
An alternative implementation, which also guarantees that all the trees will have depth at most
8.5 Path Compression
Path compression is performed during a find operation and is independent of the strategy used to perform unions. Suppose the operation is
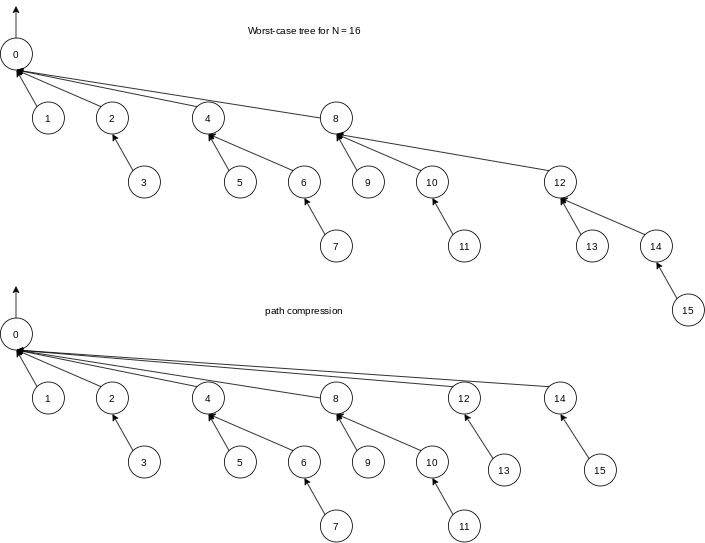
Path compression is perfectly compatible with union-by-size, and thus both routines can be implemented at the same time.
Path compression is not entirely compatible with union-by-height, because path compression can change the heights of the trees. It is not at all clear how to recompute them efficiently. The answer is do not!! Then the heights stored for each tree become estimated heights (sometimes known as ranks), but it turns out that union-by-rank (which is what this has now become) is just as efficient in theory as union-by-size.
8.6 Worst Case for Union-by-Rank and Path Compression
When both heuristics are used, the algorithm is almost linear in the worst case. Specifically, the time required in the worst case is
8.6.1 Slowly Growing Functions
Consider the recurrence:
In this equation,
There are the solution for
8.6.2 An Analysis By Recursive Decomposition
Lemma 8.1.
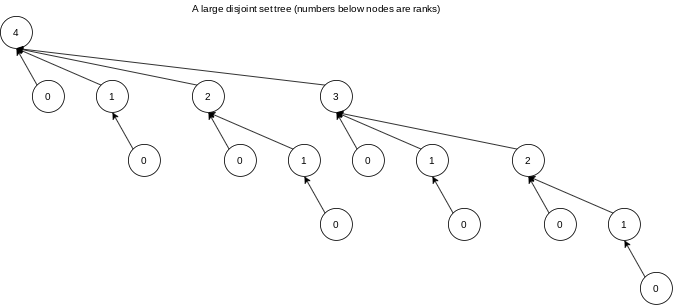
When executing a sequence of union instructions, a node of rank
Proof.
By induction. The basis
Lemma 8.2.
At any point in the union/find algorithm, the ranks of the nodes on a path from the leaf to a root increase monotonically.
Proof.
The lemma is obvious if there is no path compression. If, after path compression, some node
Partial Path Compression
A partial find operation specifies the search item and the node up to which the path compression is performed.
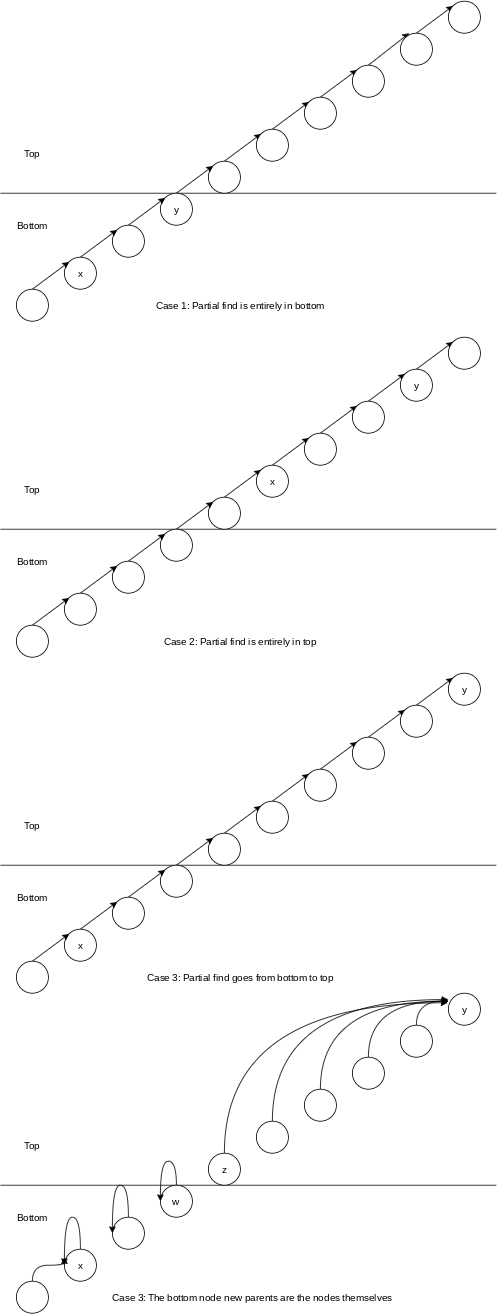
A Recursive Decomposition
What we would like to do next is to divide each tree into two halves: a top half and a bottom half. We would then like to ensure that the number of partial find operations in the top half plus the number of partial find operations in the bottom half is exactly the same as the total number of partial find operations. We would then like to write a formula for the total path compression cost in the tree in terms of the path compression cost in the top half plus the path compression cost in the bottom half.
Let
Lemma 8.3.
Proof.
In cases
Lemma 8.4.
Let
Proof.
The path compression that is performed in each of the three cases is covered by
If union-by-rank is used, then by Lemma
Lemma 8.5.
Let
Proof.
Substitute
Theorem 8.1.
Proof.
We start with Lemmas
Observe that in the top half, there are only nodes of rank
Combining terms,
Select
Equivalently, since according to Lemma
Let
which implies
Theorem 8.2.
Any sequence of
Proof.
The bound is immediate from Theorem
8.6.3 An O(M log* N) Bound
Theorem 8.3.
Proof.
From Lemma
and by Theorem
Rearranging and combining terms yields
So choose
Rearranging as in Theorem
This time, let
which implies
8.6.4 An O(Ma(M,N)) Bound
Theorem 8.4.
Proof.
Following the steps in the proof of Theorem
Needless to say, we could continue this ad-infinitim. Thus with a bit of math, we get a progression of bounds:
$$
\begin{align}
C(M, N, r) &< 2M + N \log^{}r \
C(M, N, r) &< 3M + N \log^{}r \
C(M, N, r) &< 4M + N \log^{}r \
C(M, N, r) &< 5M + N \log^{****}r \
C(M, N, r) &< 6M + N \log^{*****} r
\end{align}
$$
Each of these bounds would seem to be better than the previous since, after all, the more $
Thus what we would like to do is to optimize the number of
Define
Then, the running time of the union/find algorithm can be bounded by
Theorem 8.5.
Any sequence of
parent changes during the finds.
Proof.
This follows from the above discussion, and the fact that
Theorem 8.6.
Any sequence of
Proof.
In Theorem
8.7 An Application
A simple algorithm to generate the maze is to start with walls everywhere (except for the entrance and exit). We then continually choose a wall randomly, and knock it down if the cells that the wall separates are not already connected to each other. If we repeat this process until the starting and ending cells are connected, then we have a maze.
