
Chapter 7 Sorting
7.2 Insertion Sort
7.2.1 The Algorithm
Insertion sort consists of
| Original | 34 | 8 | 64 | 51 | 32 | 21 | Positions Moved |
|---|---|---|---|---|---|---|---|
| After p = 1 | 8 | 34 | 64 | 51 | 32 | 21 | 1 |
| After p = 2 | 8 | 34 | 64 | 51 | 32 | 21 | 0 |
| After p = 3 | 8 | 34 | 51 | 64 | 32 | 21 | 1 |
| After p = 4 | 8 | 32 | 34 | 51 | 64 | 21 | 3 |
| After p = 5 | 8 | 21 | 32 | 34 | 51 | 64 | 4 |
public static <AnyType extends Comparable<? super AnyType>> void insertionSort(AnyType[] a) {
int j;
for(int p = 1; p < a.length; p++) {
AnyType tmp = a[p];
for(j = p; j > 0 && tmp.compareTo(a[j - 1]) < 0; j--)
a[j] = a[j - 1];
a[j] = tmp;
}
}7.2.2 Analysis of Insertion Sort
Because of the nested loops, each of which can take
If the input is presorted, the running time is
7.3 A Lower Bound for Simple Sorting Algorithms
An inversion in an array of numbers is any ordered pair
We can compute precise bounds on the average running time of insertion sort by computing the average number of inversions in a permutation.
Theorem 7.1.
The average number of inversions in an array of
Proof.
For any list,
Theorem 7.2.
Any algorithm that sorts by exchanging adjacent elements requires
Proof.
The average number of inversions is initially
7.4 Shellsort
Shellsort works by comparing elements that are distant; the distance between comparisons decreases as the algorithm runs until the last phase, in which adjacent elements are compared. For this reason, Shellsort is sometimes referred to as diminishing increment sort.
Shellsort uses a sequence,
| Original | 81 | 94 | 11 | 96 | 12 | 35 | 17 | 95 | 28 | 58 | 41 | 75 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| After 5-sort | 35 | 17 | 11 | 28 | 12 | 41 | 75 | 15 | 96 | 58 | 81 | 94 | 95 |
| After 3-sort | 28 | 12 | 11 | 35 | 15 | 41 | 58 | 17 | 94 | 75 | 81 | 96 | 95 |
| After 1-sort | 11 | 12 | 15 | 17 | 28 | 35 | 41 | 58 | 75 | 81 | 94 | 95 | 96 |
The general strategy to
A popular (but poor) choice for increment sequence is to use the sequence suggested by Shell:
public static <AnyType extends Comparable<? super AnyType>> void shellsort(AnyType[] a) {
int j;
for(int gap = a.length / 2; gap > 0; gap /= 2)
for(int i = gap; i < a.length; i++) {
AnyType tmp = a[i];
for(j = i; j >= gap && tmp.compareTo(a[j - gap]) < 0; j -= gap)
a[j] = a[j - gap];
a[j] = tmp;
}
}7.4.1 Worst-Case Analysis of Shellsort
Theorem 7.3.
The worst-case running time of Shellsort, using Shell’s increments, is
Proof.
The proof requires showing not only an upper bound on the worst-case running time but also showing that there exists some input that actually takes
As we have observed before, a pass with increment
Theorem 7.4.
The worst-case running time of Shellsort using Hibbard’s increments is
Proof.
We will prove only the upper bound here.
When we come to
Now,
This tells us that the body of the innermost for loop can be executed at most
Using the fact that about half the increments satisfy
Because both sums are geometric series, and since
The average-case running time of Shellsort, using Hibbard’s increments, is thought to be
Sedgewick has proposed several increment sequences that give an
7.5 Heapsort
We then perform deleteMin operations. The elements leave the heap smallest first, in sorted order. By recording these elements in a second array and then copying the array back, we sort deleteMin takes
Notice that the extra time spent copying the second array back to the first is only
A clever way to avoid using a second array makes use of the fact that after each deleteMin, the heap shrinks by
private static int leftChild(int i) {
return 2 * i + 1;
}
private static <AnyType extends Comparable<? super AnyType>> void percDown(AnyType[] a, int i, int n) {
int child;
AnyType tmp;
for(tmp = a[i]; leftChild(i) < n; i = child) {
child = leftChild(i);
if(child != n - 1 && a[child].compareTo(a[child + 1]) < 0)
child++;
if(tmp.compareTo(a[child]) < 0)
a[i] = a[child];
else
break;
}
a[i] = tmp;
}
public static <AnyType extends Comparable<? super AnyType>> void heapsort(AnyType[] a) {
for(int i = a.length / 2 - 1; i >= 0; i--)
percDown(a, i, a.length);
for(int i = a.length - 1; i > 0; i--) {
swapReferences(a, 0, i);
percDown(a, 0, i);
}
}7.5.1 Analysis of Heapsort
The first phase, which constitutes the building of the heap, uses less than deleteMax uses at most less than
Experiments have shown that the performance of heapsort is extremely consistent: On average it uses only slightly fewer comparisons than the worst-case bound suggests.
Theorem 7.5.
The average number of comparisons used to heapsort a random permutation of
Proof.
The heap construction phase uses
Suppose the deleteMax pushes the root element down
Let
Because level deleteMax sequences is at most
A simple algebraic manipulation shows that for a given sequence
Because each deleteMax sequences that require cost exactly equal to deleteMax sequences for each of these cost sequences. A bound of
The total number of heaps with cost sequence less than
If we choose
7.6 Mergesort
Mergesort runs in
The fundamental operation in this algorithm is merging two sorted lists.
The time to merge two sorted lists is clearly linear, because at most
The merge routine is subtle. If a temporary array is declared locally for each recursive call of merge, then there could be
private static <AnyType extends Comparable<? super AnyType>> void mergeSort(AnyType[] a, AnyType[] tmpArray, int left, int right) {
if(left < right) {
int center = (left + right) / 2;
mergeSort(a, tmpArray, left, center);
mergeSort(a, tmpArray, center + 1, right);
merge(a, tmpArray, left, center + 1, right);
}
}
public static <AnyType extends Comparable<? super AnyType>> void mergeSort(AnyType[] a) {
AnyType[] tmpArray = (AnyType[])new Comparable[a.length];
mergeSort(a, tmpArray, 0, a.length - 1);
}
private static <AnyType extends Comparable<? super AnyType>> void merge(AnyType[] a, AnyType[] tmpArray, int leftPos, int rightPos, int rightEnd) {
int leftEnd = rightPos - 1;
int tmpPos = leftPos;
int numElements = rightEnd - leftPos + 1;
while(leftPos <= leftEnd && rightPos <= rightEnd)
if(a[leftPos].compareTo(a[rightPos]) <= 0)
tmpArray[tmpPos++] = a[leftPos++];
else
tmpArray[tmpPos++] = a[rightPos++];
while(leftPos <= leftEnd)
tmpArray[tmpPos++] = a[leftPos++];
while(rightPos <= rightEnd)
tmpArray[tmpPos++] = a[rightPos++];
for(int i = 0; i < numElements; i++, rightEnd--)
a[rightEnd] = tmpArray[rightEnd];
}7.6.1 Analysis of Mergesort
We will assume that
This is a standard recurrence relation, which can be solved several ways. We will show two methods. The first idea is to divide the recurrence relation through by
This equation is valid for any
This means that we add all of the terms on the left-hand side and set the result equal to the sum of all of the terms on the right-hand side. Observe that the term
Multiplying through by
An alternative method is to substitute the recurrence relation continually on the right-hand side.
Using
7.7 Quicksort
Quicksort‘s average running time is
The classic quicksort algorithm to sort an array
- If the number of elements in
is or , then return. - Pick any element
in . This is called the pivot. - Partition
(the remaining elements in ) into two disjoint groups: , and . - Return {
) followed by followed by }.
It should be clear that this algorithm works, but it is not clear why it is any faster than mergesort. Like mergesort, it recursively solves two subproblems and requires linear additional work (step 3), but, unlike mergesort, the subproblems are not guaranteed to be of equal size, which is potentially bad. The reason that quicksort is faster is that the partitioning step can actually be performed in place and very efficiently. This efficiency can more than make up for the lack of equal-sized recursive calls.
7.7.1 Picking the Pivot
Although the algorithm as described works no matter which element is chosen as the pivot, some choices are obviously better than others.
A Wrong Way
The popular, uninformed choice is to use the first element as the pivot. This is acceptable if the input is random, but if the input is presorted or in reverse order, then the pivot provides a poor partition, because either all the elements go into
Median-of-Three Partitioning
The median of a group of
The first step is to get the pivot element out of the way by swapping it with the last element.
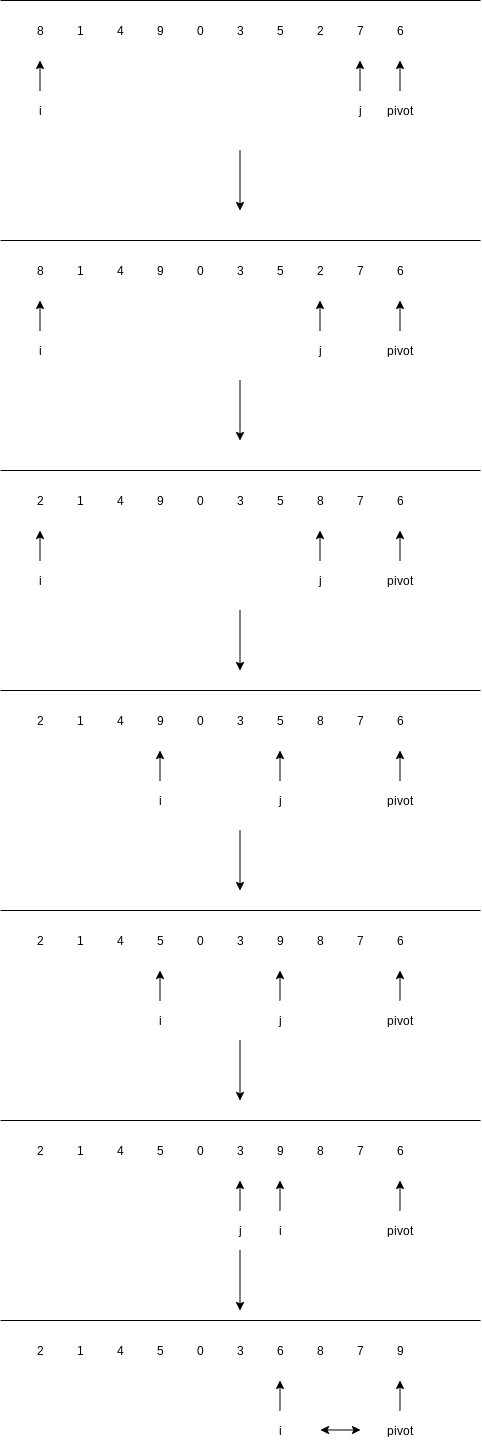
One important detail we must consider is how to handle elements that are equal to the pivot. The questions are whether or not
Thus, we find that it is better to do the unnecessary swaps and create even subarrays than to risk wildly uneven subarrays. Therefore, we will have both
7.7.3 Small Arrays
For very small arrays (
7.7.4 Actual Quicksort Routines
The first routine to deal with is pivot selection. The easiest way to do this is to sort a[left], a[right], and a[center] in place. This has the extra advantage that the smallest of the three winds up in a[left], which is where the partitioning step would put it anyway. The largest winds up in a[right], which is also the correct place, since it is larger than the pivot. Therefore, we can place the pivot in a[right - 1] and initialize i and j to left + 1 and right - 2 in the partition phase. Yet another benefit is that because a[left] is smaller than the pivot, it will act as a sentinel for j. Thus, we do not need to worry about j running past the end. Since i will stop on elements equal to the pivot, storing the pivot in a[right-1] provides a sentinel for i.
private static <AnyType extends Comparable<? super AnyType>> AnyType median3(AnyType[] a, int left, int right) {
int center = (left + right) / 2;
if(a[center].compareTo(a[left]) < 0)
swapReferences(a, left, center);
if(a[right].compareTo(a[left]) < 0)
swapReferences(a, left, right);
if(a[right].compareTo(a[center]) < 0)
swapReferences(a, center, right);
swapReferences(a, center, right - 1);
return a[right - 1];
}
public static <AnyType extends Comparable<? super AnyType>> void quicksort(AnyType [ ] a) {
quicksort(a, 0, a.length - 1);
}
private static <AnyType extends Comparable<? super AnyType>> void quicksort(AnyType[] a, int left, int right) {
if(left + CUTOFF <= right) {
AnyType pivot = median3(a, left, right);
int i = left, j = right - 1;
for(;;) {
while(a[++i].compareTo(pivot) < 0) {}
while(a[--j].compareTo(pivot) > 0) { }
if(i < j)
swapReferences(a, i, j);
else
break;
}
swapReferences( a, i, right - 1 );
quicksort(a, left, i - 1);
quicksort(a, i + 1, right);
} else
insertionSort( a, left, right );
}7.7.5 Analysis of Quicksort
The running time of quicksort is equal to the running time of the two recursive calls plus the linear time spent in the partition.
Worst-Case Analysis
The pivot is the smallest element, all the time. Then
We telescope. Thus
Adding up all these equations yields
Best-Case Analysis
In the best case, the pivot is in the middle. To simplify the math, we assume that the two subarrays are each exactly half the size of the original.
Average-Case Analysis
For the average case, we assume that each of the sizes for
With this assumption, the average value of
We note that we can telescope with one more equation.
We rearrange terms and drop the insignificant
Now we can telescope.
The sum is about
7.7.6 A Linear-Expected-Time Algorithm for Selection
The algorithm we present to find the
- If
, then and return the element in as the answer. If a cutoff for small arrays is being used and , then sort and return the th smallest element. - Pick a pivot element,
. - Partition
into and , as was done with quicksort. - If
, then the th smallest element must be in . In this case, return . If , then the pivot is the th smallest element and we can return it as the answer. Otherwise, the th smallest element lies in , and it is the st smallest element in . We make a recursive call and return .
7.8 A General Lower Bound for Sorting
7.8.1 Decision Trees
A decision tree is an abstraction used to prove lower bounds.
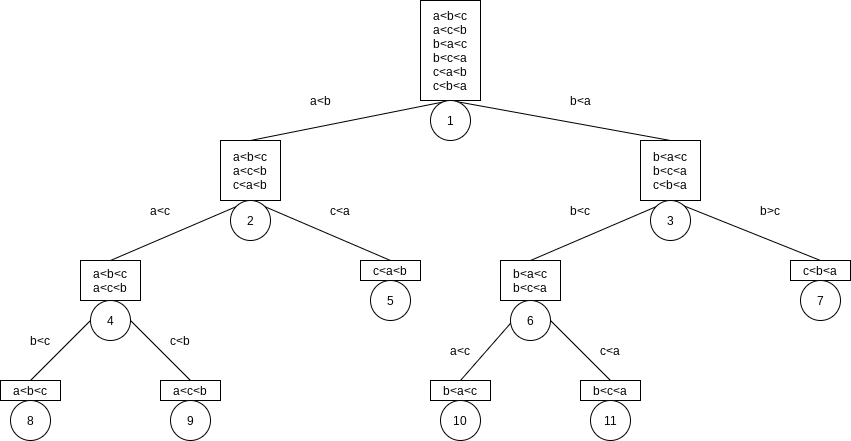
Every algorithm that sorts by using only comparisons can be represented by a decision tree. The number of comparisons used by the sorting algorithm is equal to the depth of the deepest leaf.
Lemma 7.1.
Let
Lemma 7.2.
A binary tree with
Theorem 7.6.
Any sorting algorithm that uses only comparisons between elements requires at least
Proof.
A decision tree to sort
Theorem 7.7.
Any sorting algorithm that uses only comparisons between elements requires
Proof.
This type of lower-bound argument, when used to prove a worst-case result, is sometimes known as an information-theoretic lower bound.
Note that
7.9 Decision-Tree Lower Bounds for Selection Problems
In this section we show additional lower bounds for selection in an N-element collection, specifically
comparisons are necessary to find the smallest item comparisons are necessary to find the two smallest items comparisons are necessary to find the median
Lemma 7.3.
If all the leaves in a decision tree are at depth
Theorem 7.8.
Any comparison-based algorithm to find the smallest element must use at least
Lemma 7.4.
The decision tree for finding the smallest of
Lemma 7.5.
The decision tree for finding the
Theorem 7.9.
Any comparison-based algorithm to find the
Theorem 7.10.
Any comparison-based algorithm to find the second smallest element must use at least
Theorem 7.11.
Any comparison-based algorithm to find the median must use at least
7.11 Linear-Time Sorts: Bucket Sort and Radix Sort
For bucket sort to work, extra information must be available. The input
The running time of radix sort is
| INITIAL ITEMS: | 064 | 008 | 216 | 512 | 027 | 729 | 000 | 001 | 343 | 125 |
|---|---|---|---|---|---|---|---|---|---|---|
| SORTED BY 1’s digit | 000 | 001 | 512 | 343 | 064 | 125 | 216 | 027 | 008 | 729 |
| SORTED BY 10’s digit: | 000 | 001 | 008 | 512 | 216 | 125 | 027 | 729 | 343 | 064 |
| SORTED BY 100’s digit: | 000 | 001 | 008 | 027 | 064 | 125 | 216 | 343 | 512 | 729 |
Counting radix sort is an alternative implementation of radix sort that avoids using ArrayLists. Instead, we maintain a count of how many items would go in each bucket; this information can go into an array